引言:賦能數據驅動
在數字化浪潮席卷全球的今天,大數據已成為驅動科學研究、商業決策和社會創新的核心引擎。建設一個功能完善、技術先進的大數據實驗室,并構建與之匹配的專業化大數據服務體系,對于高校、科研院所及企業而言,是從海量數據中挖掘價值、培養復合型人才、保持核心競爭力的戰略舉措。本文旨在提供一個集硬件平臺、軟件生態、人才培養與對外服務于一體的綜合性解決方案。
一、大數據實驗室建設:夯實基礎設施
大數據實驗室的建設絕非簡單的設備堆砌,而是一個系統性工程,需兼顧計算能力、存儲容量、網絡環境與軟件生態。
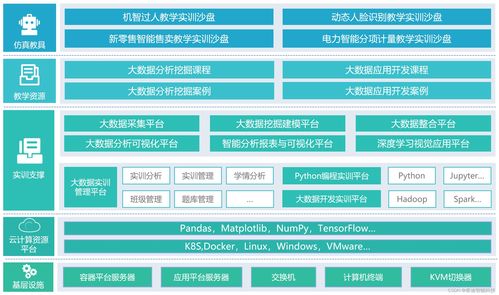
- 硬件基礎設施層:
- 計算集群: 構建基于Hadoop/Spark的分布式計算集群,采用高性能服務器,支持橫向擴展(Scale-out)。根據需求,可集成GPU服務器以支持機器學習與深度學習任務。
- 存儲系統: 部署高可靠、可擴展的分布式存儲系統(如HDFS、Ceph),滿足海量結構與非結構化數據的存儲需求,并配置SSD緩存層以加速熱點數據訪問。
- 網絡環境: 搭建萬兆乃至更高速率的內部網絡,確保計算節點間數據交換的高帶寬與低延遲,同時保障實驗室網絡與外部數據源的安全、穩定連接。
- 可視化與交互終端: 配備大屏數據可視化展示系統及高性能工作站,用于數據探索、模型調優和成果演示。
- 軟件平臺與工具層:
- 大數據處理平臺: 集成Hadoop、Spark、Flink等主流分布式計算框架,提供批處理與流處理能力。
- 數據管理與數據庫: 部署HBase、Hive等NoSQL/數據倉庫工具,并可根據需要引入MPP數據庫(如ClickHouse)或關系型數據庫。
- 數據分析與挖掘套件: 安裝Python、R語言環境及TensorFlow、PyTorch、Scikit-learn等機器學習/深度學習庫,提供Jupyter Notebook、RStudio等交互式開發環境。
- 數據可視化工具: 集成Tableau、Superset、ECharts等工具,支持從數據到洞察的直觀呈現。
- 運維與管理平臺: 采用Ambari、Cloudera Manager等工具實現集群的監控、管理和自動化部署,提升運維效率。
- 數據資源與安全體系:
- 數據源接入: 設計接口,支持接入公開數據集、行業數據、物聯網設備數據及企業內部數據(需經脫敏和安全審核)。
- 安全與權限管理: 建立多層次安全防護,包括網絡隔離、用戶身份認證、細粒度數據訪問權限控制、操作審計日志等,確保數據全生命周期的安全合規。
二、大數據服務體系:釋放數據價值
實驗室不僅是技術研發基地,更應成為對外提供數據價值轉化服務的窗口。大數據服務體系旨在將實驗室能力產品化、服務化。
- 數據工程服務:
- 數據采集與集成: 幫助企業/機構完成多源、異構數據的匯聚與整合,構建統一的數據湖或數據倉庫。
- 數據治理與質量提升: 提供數據標準制定、元數據管理、數據質量評估與清洗服務,確保數據可信、可用。
- 數據分析與洞察服務:
- 描述性與診斷性分析: 通過報表、儀表盤等形式,幫助客戶理解業務現狀、追溯問題根源。
- 預測性與規范性分析: 運用統計模型與機器學習算法,進行趨勢預測、用戶分群、風險預警,并提供優化決策建議。
- 人工智能模型開發服務:
- 定制化模型開發: 針對圖像識別、自然語言處理、智能推薦等特定場景,開發、訓練并部署AI模型。
- 模型運維與優化(MLOps): 提供模型上線后的持續監控、性能評估與迭代優化服務。
- 咨詢與培訓服務:
- 大數據戰略咨詢: 協助客戶制定數據戰略規劃、技術選型建議與實施路徑設計。
- 技術培訓與認證: 面向企業員工或學生,提供大數據技術棧(如Hadoop、Spark、Python數據分析)的系統化實戰培訓,并可對接國際認證體系。
三、一體化運營與持續發展
為確保實驗室與服務體系的長期活力,需建立科學的運營機制:
- 團隊建設: 組建由架構師、數據工程師、數據科學家、分析師和項目經理組成的跨學科團隊。
- 項目管理: 采用敏捷開發模式,以項目制推動服務交付,確保成果可衡量、可交付。
- 產學研合作: 積極與產業界合作,承接真實業務場景下的數據挑戰,反哺教學與科研,促進成果轉化。
- 持續演進: 跟蹤大數據與AI技術前沿(如云原生、數據湖倉一體、AutoML等),定期對實驗室技術棧和服務能力進行升級迭代。
###
大數據實驗室建設與大數據服務體系的構建,是一個從“硬”到“軟”、從“內”到“外”的有機整體。一個成功的解決方案,不僅能打造一個強大的技術研發環境,更能建立起一套可持續的數據價值變現和能力輸出模式,最終成為驅動組織數字化轉型與智能化升級的“智慧大腦”和“創新引擎。通過本方案的實施,客戶將獲得從基礎設施到高端服務、從人才培養到商業應用的全方位能力提升,在數據時代贏得先機。